今年上半年,由于疫情原因,Switch大火,Switch平台上有许多款体感游戏,比如:健身环大冒险、马力欧赛车、舞力全开。这些游戏凭着“硬核健身”的标签吸引了大量玩家,通过两个手柄配合记录传感数据,就能检测到跑步、抬腿、深蹲等动作,这种精准的体感动作感知吸引了不少玩家。
但是,现在不需要Switch!不需要体感手柄!树莓派+visionseed!你也可以动手自己实现属于你的体感游戏!今天,小编就来教大家,如何从0开始,实现一款基于AI的体感吃火锅游戏~
先为大家展示一下游戏的全流程:
 1. 玩家张嘴,游戏开始,计时30s
1. 玩家张嘴,游戏开始,计时30s
 2. 玩家张嘴触碰到食物,食物消失,得分加一
2. 玩家张嘴触碰到食物,食物消失,得分加一
 3. 游戏结束,显示得分
3. 游戏结束,显示得分
什么是树莓派呢?
树莓派(Raspberry Pi)是尺寸仅有信用卡大小的一个小型电脑,您可以将树莓派连接电视、显示器、键盘鼠标等设备使用。
树莓派能替代日常桌面计算机的多种用途,包括文字处理、电子表格、媒体中心甚至是游戏。并且树莓派还可以播放高至1080p的高清视频。

神奇的VisionSeed
提到AI体感游戏,大家第一时间想到的可能是高深的AI算法训练和复杂的工程部署,来自不同厂家的芯片、系统框架、AI算法之间,常常存在一定的兼容性或效率问题,导致AI产品开发周期长,算法效果不理想。以前用树莓派3B跑过人脸检测,用OpenCV的Haar Cascades算法,要160多毫秒才能跑完一帧人脸检测。如果用效果更好的深度神经网络模型,比如通过ncnn加速框架跑MobileNet-SSD模型,则需要260多毫秒,再跑一个关键点定位模型估计还要几十毫秒,整体帧率就只有3fps了。
当当当,是时候请出一个神奇的模块了,他内置了一颗AI加速芯片,单周期可以运行512次乘加运算,硬件支持卷积、池化、全连接等操作,还带了两颗手机摄像头模组,直接能对拍到的图像跑AI算法进行分析,通过UART输出分析后的结果,非常有意思!
这就是我们隆重推出的腾讯优图AI视觉模组VisionSeed!

目前VisionSeed模块提供的算法有:人脸检测、90点关键点定位、姿态角解算、人脸识别,还能够把自己训练的模型下载到模块上的AI芯片中运行。
我们先通过腾讯提供的PC端配置工具,看看模块上的AI算法输出的信息:
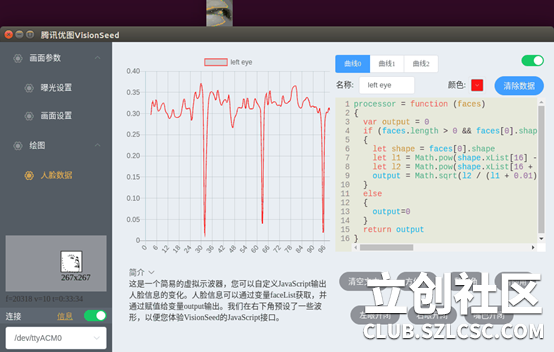
通过USB把VisionSeed连上电脑后,识别出来一个video0设备和ttyACM0设备,用配置工具打开ttyACM0,就能源源不断的获取到实时分析数据了,左下角马上显示出了我的脸部关键点,随着我眨眼、摇头、张嘴,这个虚拟的小人也跟着变化,数据可视化界面上,选择“左眼开闭”,曲线就开始滚动起来了,我每次眨眼,曲线就出现一个向下的尖峰,如果闭眼,曲线就稳定在0.05以下的位置,非常灵敏!
VisionSeed中的关键算法VisionSeed这么牛,那我们直接拿它提供的90关键点定位算法去检测张闭嘴呀!
通过下面的内置算法ID,我们可以获取对应的算法结果:
YtVisionSeedModel.FACE_DETECTION: 人脸检测
YtVisionSeedModel.FACE_LANDMARK: 人脸关键点定位(90点)
YtVisionSeedModel.FACE_POSE: 人脸姿态(roll, yaw,picth)
YtVisionSeedModel.FACE_RECOGNITION: 人脸识别
我们要把这个模组与树莓派连接,需要一根type-c和usb的数据线,如下图所示连接。启动树莓派后,模组上会亮起绿灯,表明两者已接通。

那么如何获取模组的摄像头数据呢?
datalink= vs.YtDataLink( serial.Serial("/dev/ttyACM0",115200,timeout=0.5) )
通过python中的pyserial模块连接串行口,再建立连接后,就可以通过getResult方法获得人脸识别、人脸姿态、人脸关键点定位等信息。
检测到的人脸数 |
faces = result.getResult([YtVisionSeedModel.FACE_DETECTION]) |
人脸框坐标 |
rect = result.getResult([YtVisionSeedModel.FACE_DETECTION, 0])
0表示检测到的第一个人脸,1表示第二个,以此类推… |
人脸关键点定位 |
shape = result.getResult([YtVisionSeedModel.FACE_DETECTION, 0, YtVisionSeedModel.FACE_LANDMARK]) |
通过rect = result.getResult([YtVisionSeedModel.FACE_DETECTION, 0]) 就可以获取到当前检测到的人脸框,rect.x,rect.y,rect.w,rect.h分别代表了人脸框的左上角横坐标、左上角纵坐标、宽度、高度。
通过shape = result.getResult([YtVisionSeedModel.FACE_DETECTION, 0,YtVisionSeedModel.FACE_LANDMARK]) 可以获取到人脸的90个配准点,下图就展示了嘴巴上的配准点

然后通过计算嘴巴的姿态去判断张闭嘴:
let l1 =faceShape.mouth[0].distence(faceShape.mouth[6])
let l2 =faceShape.mouth[3].distence(faceShape.mouth[9])
output = l2 / (l1 + 0.01)
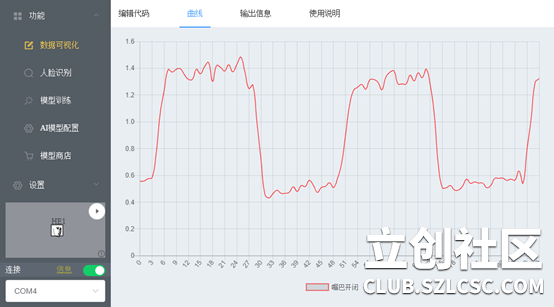
上图的曲线所描绘的就是当我的嘴巴张开时,出现峰值;当我的嘴巴闭合时,出现谷值。纵坐标值output所表现的就是嘴巴的开闭程度。
游戏设计
我们将用python语言来设计这个游戏,其中涉及了几个重要的第三方库:cv2、cocos、visionseed。
1. cv2:通过cap = cv2.VideoCapture(0)读取模组的摄像头
2. cocos:是用于构建游戏的框架。这个引擎就跟拍电影一样,有导演(Director),有大背景(Scene),还有背景上的小修饰物(Layer),还有人物(Sprite)。
3. visionseed:通过导入visionseed库,通过库中的一些方法获取人脸的信息。
类的设计
正如之前所展示的游戏视频,此游戏主要分为三个场景:游戏开始、游戏进行中、游戏结束。三个场景形成一个闭环。
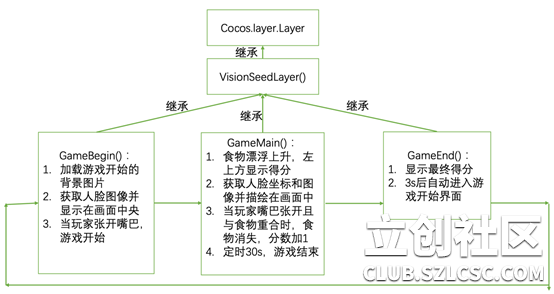
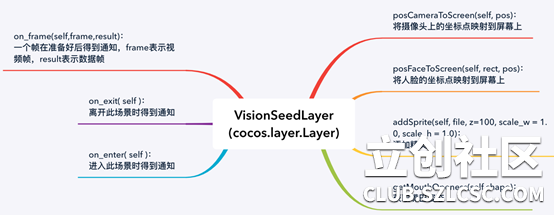
其次,我们要定义一个类VisionSeedLayer,继承自cocos.layer.Layer,实现下面这些方法:
1. on_enter( )实现场景的进入
2. on_exit( )实现场景的离开
3. on_frame( )显示每一帧的画面
4. addSprite( )在图层上添加精灵
5. posFaceToScreen( )将人脸坐标映射到屏幕坐标上
6. recvMsg( )通过result,msg =datalink.recvRunOnce()接收result数据帧
7. recvFrame( )通过ret, frame = cap.read( )接收frame视频帧
如下图所示
如下图,展示了实现GameBegin( )中的三个主事件的核心代码:

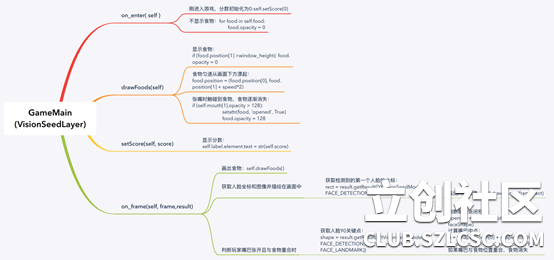
如下图,展示了实现GameMain( )中的四个主事件的核心代码:
最后我们就能实现一个简单又真实的体感游戏啦!
后记
其实VisionSeed不仅仅是个集成了摄像头+AI芯片的模块,AI算法才是效果的保证,他内置了腾讯优图的算法,效果过硬,一直处于业界领先地位,以前一般在腾讯内部产品中应用,比如微信刷脸支付。现在通过VisionSeed人工智能视觉模块,开放给外界,你我也能接触到世界一流的腾讯人工智能算法,甚至能应用在自己的产品中,实在是非常开心。相信腾讯的开放,会惠及更多创业者和爱好者们。
另外,模块内还包括了人脸识别功能,通过附带工具软件管理数据库,能够实时离线识别库中的身份,非常强大,能做出很多有意思的东西,等你一起来探索!




 返回列表
返回列表


 发表于2020-07-21 10:58:03
发表于2020-07-21 10:58:03



 回复
回复
 收藏
收藏
 举报
举报

